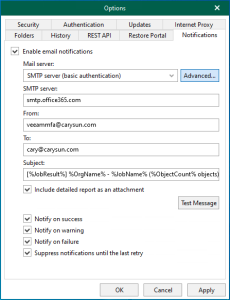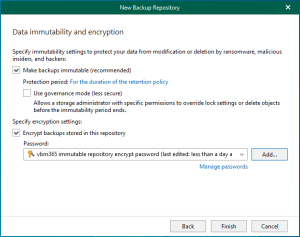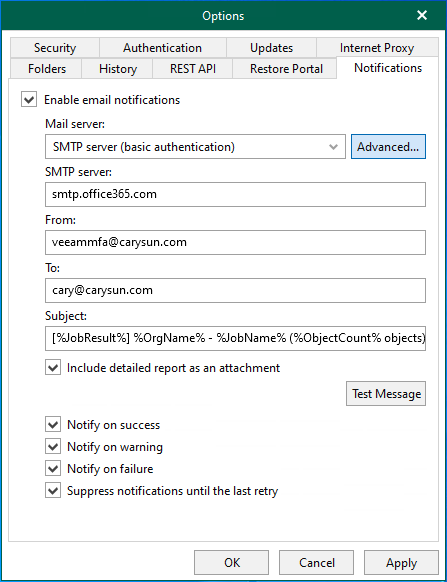
You can configure Microsoft 365 with an MFA-enabled account for notification settings. This...
Hyper-V
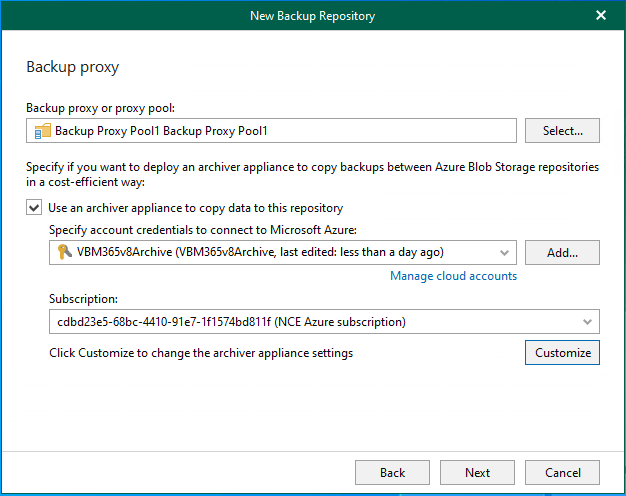
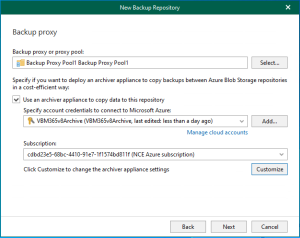
Veeam Backup for Microsoft 365 uses the Veeam Azure archiver appliance, a small virtual...
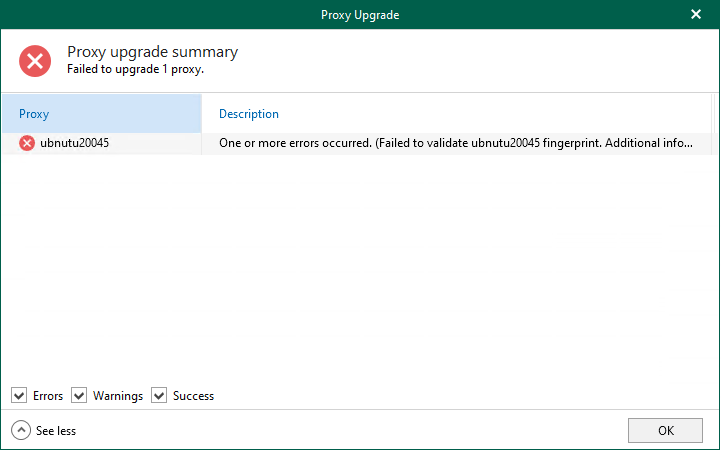
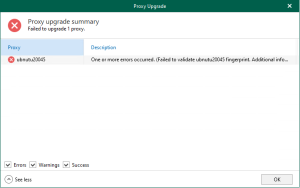
The upgrade failed because the SSH public key fingerprint of the Linux proxy does...

Veeam released Veeam Backup for Microsoft 365 v8.3.0.2201 on December 18, 2025, which included...
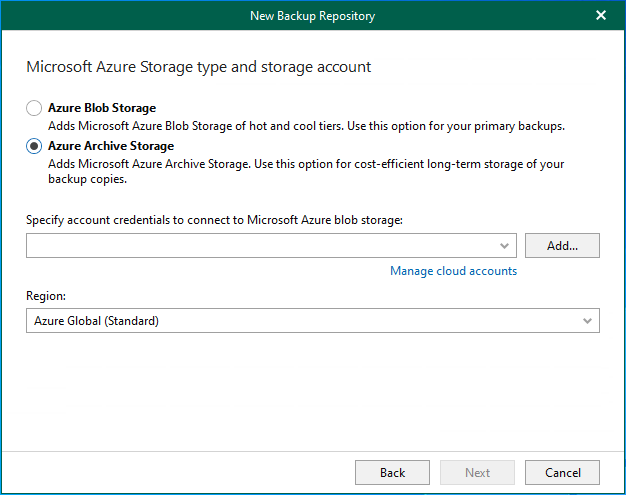
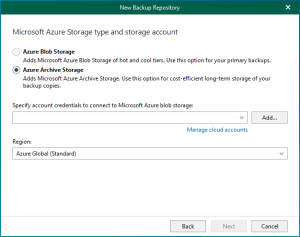
In Veeam Backup for Microsoft 365 version 8.2, adding a Microsoft Azure Archive Storage...
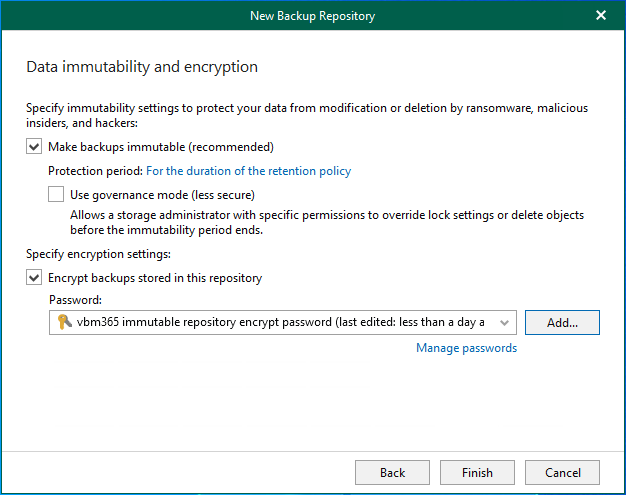
Integrating Microsoft Azure Blob Storage repositories with immutability requires configuring both the Azure storage...
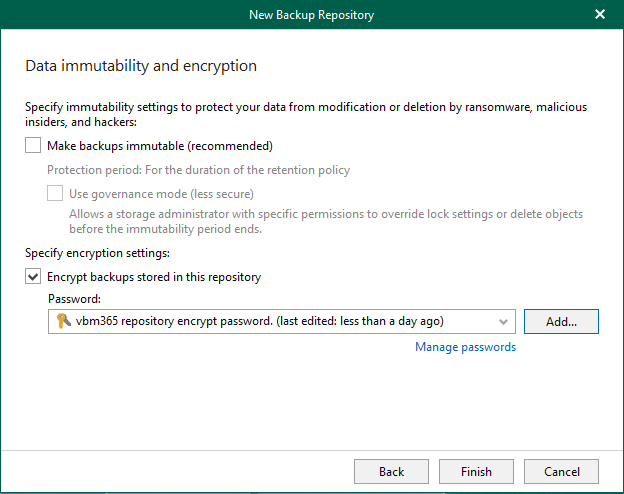
We will add Azure Blob Storage, which lacks immutability, to our Veeam Backup for...
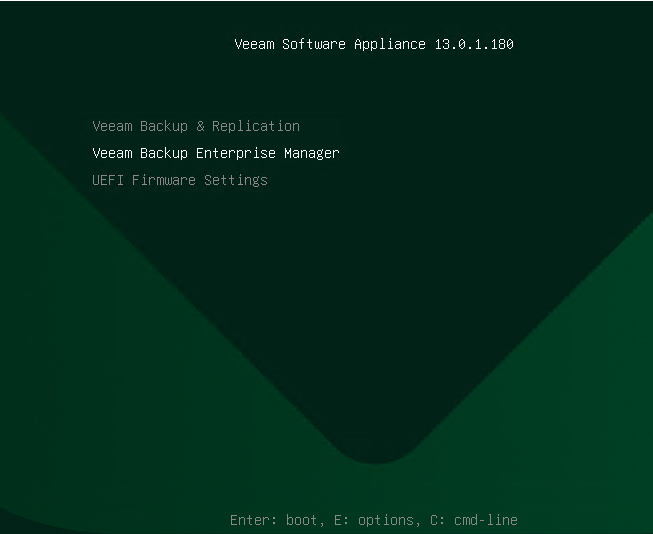
To install the Veeam Backup Enterprise Manager on Linux (Veeam Software Appliance) at Hyper-V...
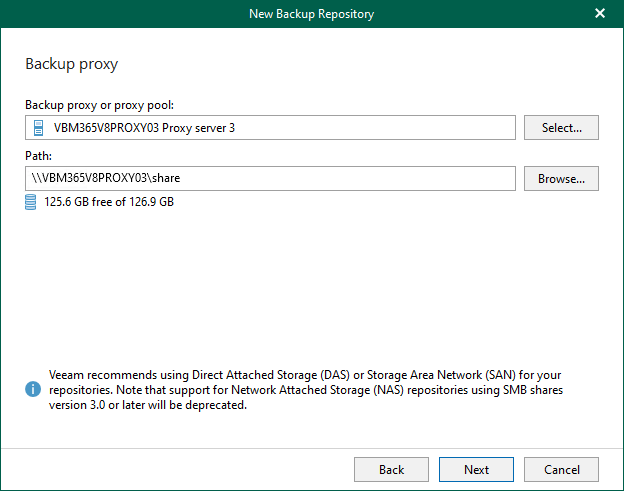
Network Attached Storage can also be used with Veeam Backup for Microsoft 365 as...

To add a local directory or Direct Attached Storage (DAS) as a backup repository...
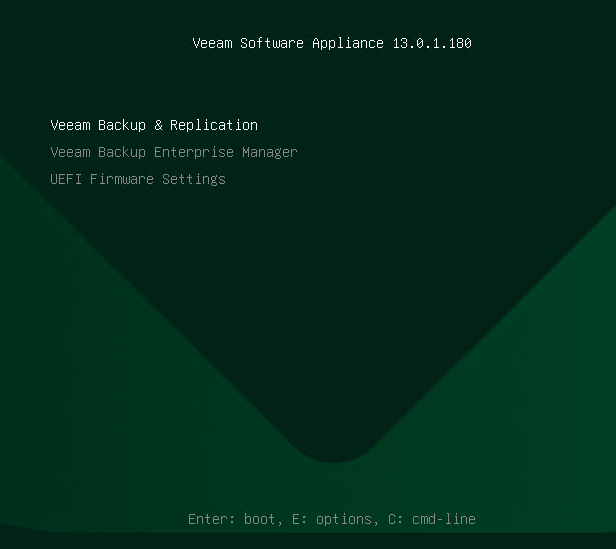
In order to install the Veeam Software Appliance (VSA) on Hyper-V 2025, you must...

Version 8 of Veeam Backup for Microsoft 365 introduced proxy pools to improve performance...
Make sure you are running Veeam Backup & Replication version 12.3.1 or later to...
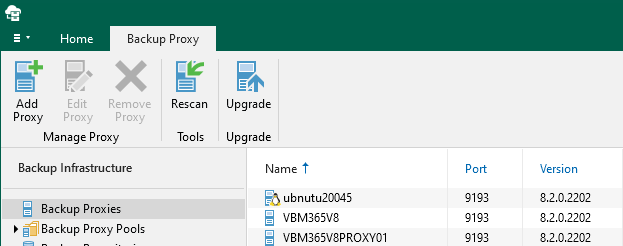
Linux Backup proxy servers are auxiliary servers that you can configure to improve performance,...
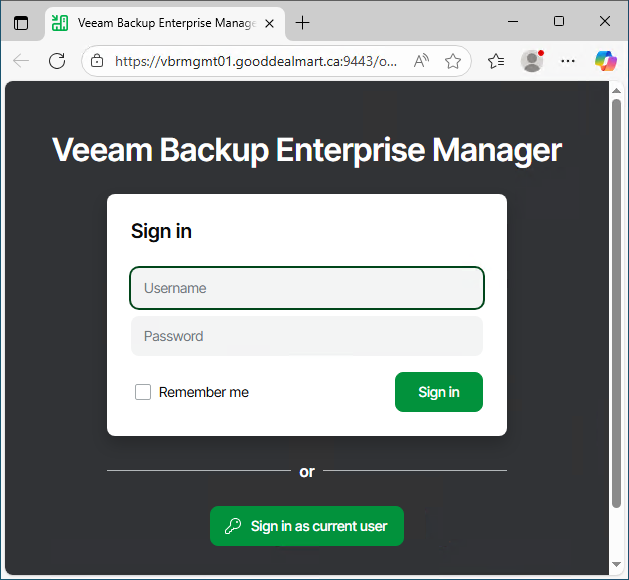
To execute an in-place upgrade of Veeam Backup Enterprise Manager on a server being...
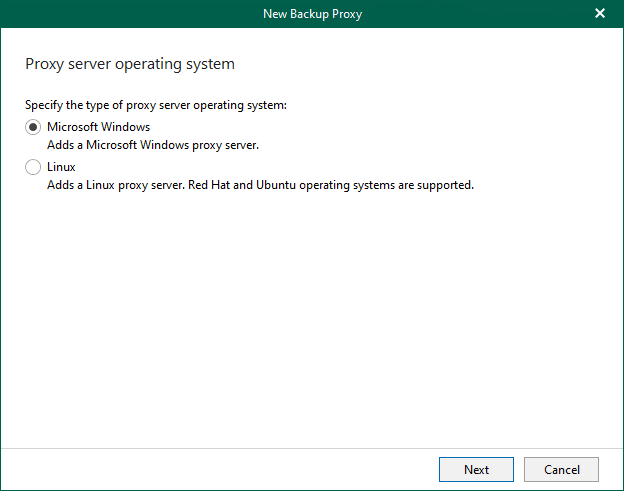
Veeam Backup for Microsoft 365 consists of Backup proxy servers, Backup Proxy Pools, Backup Local...

The Veeam Backup & Replication console is installed on the backup server automatically when...
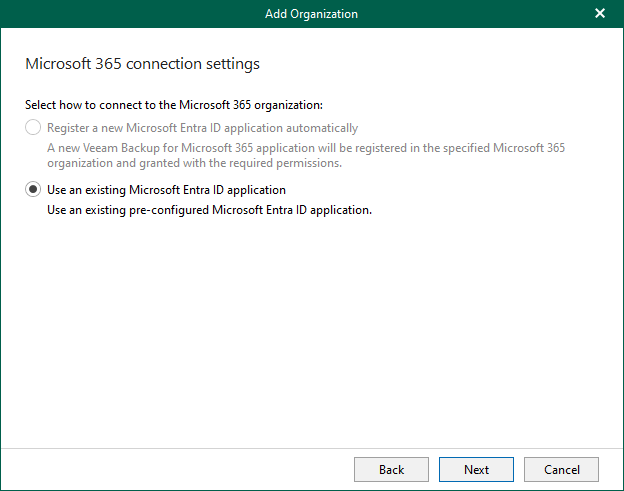
When you add an organization using the modern app-only authentication method, Veeam Backup for...

Veeam Backup Enterprise Manager v13 is a centralized management and reporting tool designed by...
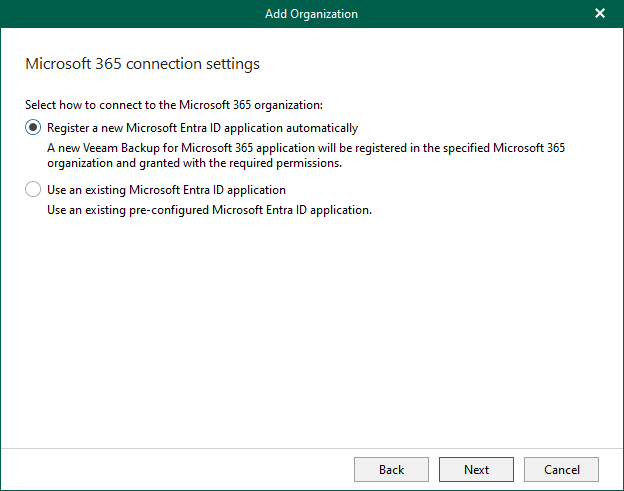
Registering a new Microsoft Entra ID application automatically is unavailable if you want to...

Veeam Backup & Replication v13 is available for Microsoft Windows as self-managed installable software...
There are benefits such as enhanced scalability, flexibility, and security when a restore portal...
When you install Veeam Backup for Microsoft 365, the PowerShell Toolkit is automatically installed...
When you install Veeam Backup for Microsoft 365, its console is automatically installed on...
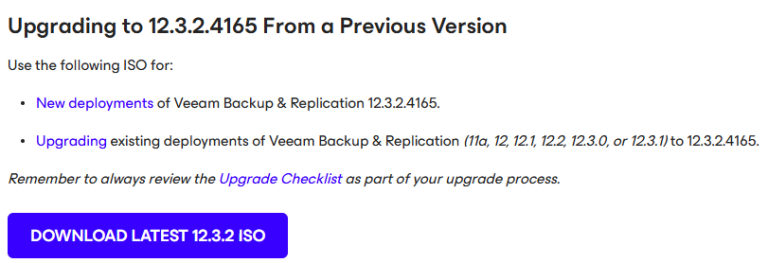
Veeam released the Backup & Replication v12.3.2.4165 on October 14, 2025.

Veeam Backup & Replication should be upgraded after Veeam Backup Enterprise Manager is upgraded.
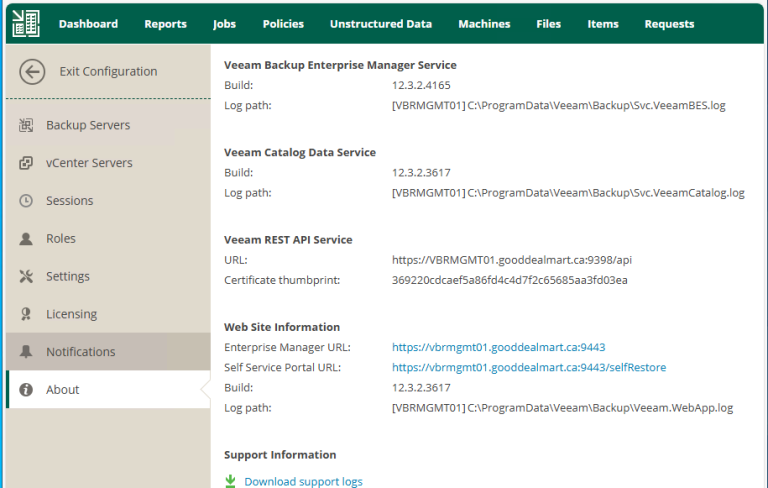
Veeam released the Backup & Replication v12.3.2.4165 on October 14, 2025.
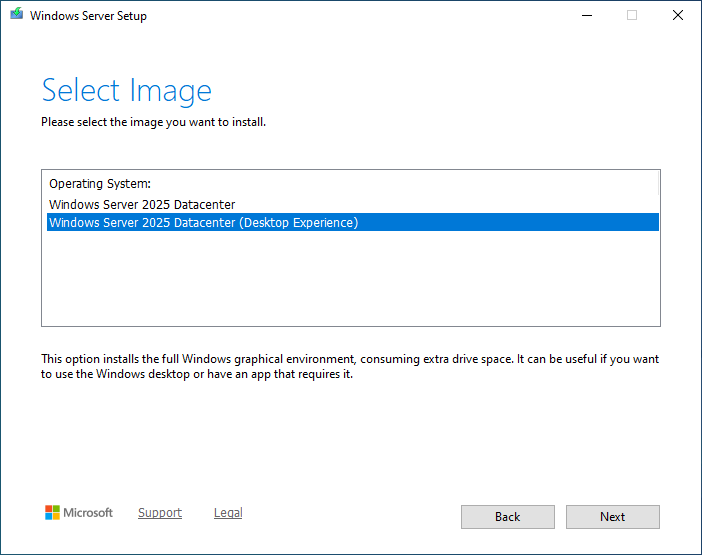
Today, I am going to show you how to perform an in-place upgrade of...
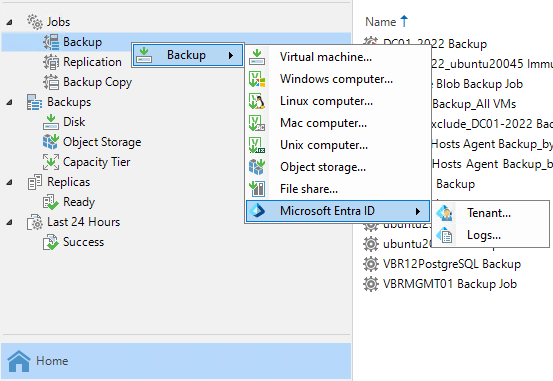
Veeam Backup for Microsoft Entra ID Logs to protect tenant audit and sign-in logs.
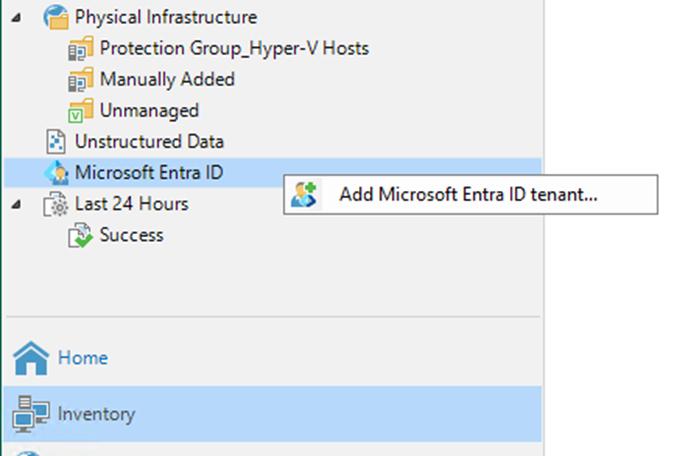
After you've added a Microsoft Entra ID tenant to the backup infrastructure, you can...